
Introducción.
El análisis de cosechas en riesgo crediticio, también conocido como vintage analysis, es una herramienta útil para evaluar el rendimiento de los préstamos en cartera y estimar el riesgo crediticio futuro. Esta técnica se basa en el seguimiento del desempeño de los préstamos durante su vida útil, lo que permite identificar patrones de comportamiento y tendencias que pueden ser utilizados para mejorar la gestión del riesgo crediticio.
El análisis de cosechas en riesgo crediticio se puede utilizar para medir la calidad de la cartera de préstamos de una institución financiera y determinar si se están tomando decisiones de crédito adecuadas. También puede ser útil para identificar problemas específicos en la cartera y tomar medidas correctivas para minimizar las pérdidas.
En este artículo, se presentará cómo realizar un análisis de cosechas en riesgo crediticio utilizando Python, una herramienta de programación que permite automatizar el análisis de datos y generar informes.
¿Qué es el análisis de cosechas en riesgo crediticio?
El análisis de cosechas en riesgo crediticio se basa en el seguimiento del desempeño de los préstamos durante su vida útil. Para realizar este análisis se requiere determinar los periodos de maduración y la segmentación de la cartera crediticia.
Los periodos de maduración pueden ser mensuales, quincenales, semanales, diarios, entre otros. Por otro lado, la segmentación se puede hacer por tipos de crédito, destino del crédito, tipos de producto, zona geográfica, actividad económica, agencia u oficina, supervisor crediticio, evaluador, entre otros.
Una vez que se han identificado las cosechas, se realiza un seguimiento del desempeño de cada grupo de préstamos a lo largo del tiempo. Esto incluye el análisis de la tasa de incumplimiento, la tasa de recuperación y la tasa de pérdida de cada cosecha en diferentes momentos de su vida útil. Estos datos se utilizan para calcular una serie de métricas clave, incluyendo la tasa de incumplimiento acumulada, la tasa de recuperación acumulada y la tasa de pérdida acumulada.
Para la elaboración se minimamente se necesita la siguiente información:
- Data de los créditos y montos desembolsado por cada periodo de maduración.
- Fecha de desembolso de cada crédito.
- Días máximo de atraso permitido (por ejemplo: 30 días)
- Monto atrasado de dichos créditos (por ejemplo: más de 30 días) durante el periodo de análisis.
- Algunas entidades agregan los créditos castigados a la cartera.
Analisis con Python.
Supongamos que este es un conjunto de datos de una empresa de préstamos, y queremos analizar la calidad de la cartera de préstamos en función del tiempo que han estado en mora. Queremos obtener un indicador vintage de mora para los préstamos, es decir, un indicador que muestre el porcentaje de préstamos que han estado en mora en un momento determinado desde que se otorgaron. Luego, queremos visualizar esta información en un mapa de calor.
Primero, importamos las bibliotecas necesarias:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as pltLuego, creamos una función que determina si un crédito esta en mora mayor a “x” días o no.
def get_balanceByDays(row,days):
if row['DiasMora'] > days:
return row['SaldoColocaciones']
else:
return 0Despues, leemos los datos desde un archivo de Excel y creamos dos nuevas columnas: “Mayor8Dias” y “Mayor30Dias”, que indican si el préstamo ha estado en mora por más de 8 días y 30 días, respectivamente para utilizamos la función que hemos creado anteriormente.
Nota: El archivo de excel debe contener mínimo las siguientes columnas:
- FechaCierre : Fecha de cierre del periodo, para el ejemplo el periodo es mensual.
- NumeroCredito : Número de crédito, debe ser único en cada periodo.
- FechaDesembolso : Fecha de desembolso del crédito.
- MontoDesembolso : Monto desembolsado del crédito.
- SaldoColocaciones : Saldo capital del crédito al cierre de cada periodo.
- DiasMora : Dias de atraso a cada cierre de periodo.
df = pd.read_excel('./datasets/anexo6.xlsx')
df['Mayor8Dias'] = df.apply(get_balanceByDays,axis=1,args=[8])
df['Mayor30Dias'] = df.apply(get_balanceByDays,axis=1,args=[30])A continuación, creamos una función que extrae el año, el mes y el día de una columna de fecha en el dataframe:
def get_date_int(df, column) :
year = df[column].dt.year
month = df[column].dt.month
day = df[column].dt.day
return year, month, dayLuego, usamos esta función para calcular la “AlturaVida” de cada préstamo, que indica cuántos meses han pasado desde que se otorgó el préstamo hasta el momento en que se cerró el informe de crédito:
anio_cierre, mes_cierre, dia_cierre = get_date_int(df, 'FechaCierre')
anio_cosecha, mes_cosecha, dia_cosecha = get_date_int(df,'FechaDesembolso')
years_diff = anio_cierre - anio_cosecha
months_diff = mes_cierre - mes_cosecha
df['AlturaVida'] = years_diff * 12 + months_diffA continuación, definimos una función que calcula el indicador de mora (Mayor30Dias/SaldoColocaciones) para cada préstamo:
#Funcion para calcular indicador de mora
def ind_mora(row):
return row['Mayor30Dias']/row['SaldoColocaciones']Luego, creamos una tabla dinámica que resume la cantidad de préstamos en mora y el saldo de los préstamos en mora por mes de desembolso. También calculamos el indicador de mora para cada mes y lo agregamos a la tabla. Observa que pasamos la data filtrada por un rango de fecha de cierre “FechaCierre”:
situacion = pd.pivot_table(df[(df['FechaCierre']=='2022-09-30') & (df['FechaDesembolso']>='2021-01-01')],
index=pd.Grouper(key='FechaDesembolso',freq='1M'),
values=["SaldoColocaciones","Mayor30Dias"],
aggfunc='sum'
)
situacion.reset_index()
situacion["indice"] = situacion.apply(ind_mora,axis=1)A continuación, generamos un dataframe cohort_data que contiene la suma de saldos de colocaciones con mora mayor a 30 días agrupados por mes de desembolso y antigüedad del crédito en meses. Este dataframe utilizamos para generar un nuevo dataframe cohort_mora que contiene la tasa de mora por cada combinación de mes de desembolso y antigüedad del crédito en meses.
cohort_data = df[df['FechaDesembolso']>='2021-01-01'].groupby(
[pd.Grouper(key='FechaDesembolso',freq='1M'),'AlturaVida']
)['Mayor30Dias'].apply(np.sum)
cohort_data = cohort_data.reset_index()
cohort_mora = cohort_data.pivot_table(
index = 'FechaDesembolso',
columns = 'AlturaVida',
values = 'Mayor30Dias'
)Luego utilizamos función groupby para generar un nuevo dataframe cohort_data_des que contiene la suma de montos desembolsados agrupados por mes de desembolso y antigüedad del crédito en meses. Este dataframe utilizamos para generar un nuevo dataframe cohort_counts_des que contiene el número de créditos desembolsados por cada combinación de mes de desembolso y antigüedad del crédito en meses. En este paso debemos filtrar por fecha de desembolso
cohort_data_des = df[df['FechaDesembolso']>='2021-01-01'].groupby(
[pd.Grouper(key='FechaDesembolso',freq='1M'),'AlturaVida']
)['MontoDesembolso'].apply(np.sum)
cohort_data_des = cohort_data_des.reset_index()
cohort_counts_des = cohort_data_des.pivot_table(
index = pd.Grouper(key='FechaDesembolso',freq='1M'),
columns = 'AlturaVida',
values = 'MontoDesembolso'
)Luego, generaremos el indicador de cosecha (indicador vintage) indVintage dividiendo el dataframe cohort_mora entre el dataframe cohort_counts_des.
indVintage = cohort_mora.divide(cohort_counts_des.iloc[:,0], axis = 0)
indVintage = (indVintage * 100).round(4)
indVintage.index = indVintage.index.strftime('%Y-%m')Visualización de datos
Una vez que hemos realizado el análisis de cosechas y hemos obtenido las métricas clave, es hora de visualizar los datos para tener una mejor comprensión de lo que están diciendo.
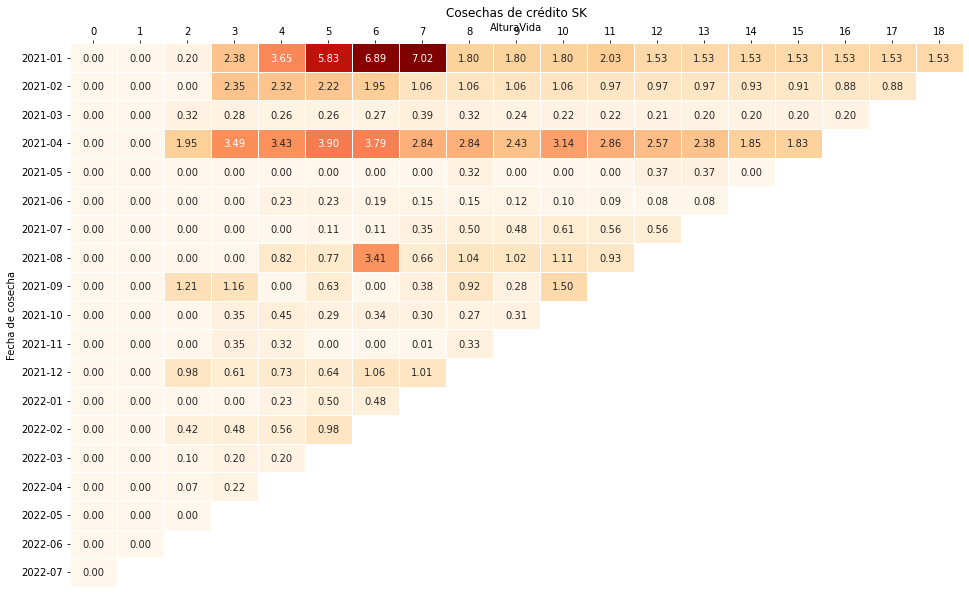
En este ejemplo, podemos utilizar un mapa de calor para mostrar cómo cambia la tasa de incumplimiento acumulada a lo largo del tiempo. Para ello, utilizaremos la biblioteca seaborn.
plt.figure(figsize = (16,10))
ax = sns.heatmap(indVintage, annot = True, cmap="OrRd", fmt='.2f',linewidths=.5,cbar=False)
ax.xaxis.tick_top()
ax.xaxis.label_position = 'top'
ax.set(title='Cosechas de crédito SK',ylabel='Fecha de cosecha')
plt.show()Este código creará un mapa de calor que muestra la tasa de incumplimiento acumulada para diferentes periodos de maduración y diferentes períodos de tiempo de atraso.
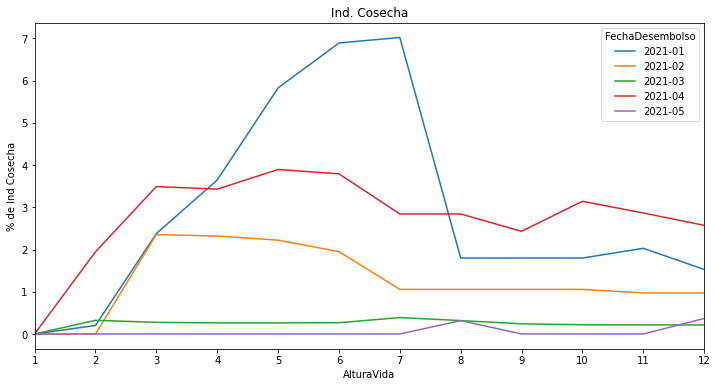
Tambien podemos crear una grafíca de lineas que muestra la evolución del indicador mes a mes.
indVintage.T[['2021-01','2021-02','2021-03','2021-04','2021-05']].plot(figsize=(12,6))
plt.title('Ind. Cosecha')
plt.xticks(np.arange(1, 12.1, 1))
plt.xlim(1, 12)
plt.ylabel('% de Ind Cosecha')Este código creara una grafíca de lineas
Conclusiones
El análisis de cosechas en riesgo crediticio es una herramienta útil para evaluar el rendimiento de los préstamos en cartera y estimar el riesgo crediticio futuro. Este tipo de análisis puede ayudar a identificar patrones de comportamiento y tendencias en la cartera de préstamos, lo que puede ser utilizado para mejorar la gestión del riesgo crediticio.
En este ejemplo, hemos utilizado Python para realizar un análisis de cosechas y calcular las métricas clave. También hemos utilizado un mapa de calor para visualizar los datos y obtener una mejor comprensión de lo que están diciendo.
Es importante tener en cuenta que el análisis de cosechas en riesgo crediticio es una técnica avanzada y que se requiere una cantidad significativa de datos para que sea efectivo. Además, la calidad de los datos es crucial para la precisión del análisis. Por lo tanto, es importante asegurarse de que se estén recopilando y almacenando los datos de manera adecuada.
En resumen, el análisis de cosechas en riesgo crediticio puede ser una herramienta valiosa para evaluar la calidad de la cartera de préstamos y tomar decisiones de crédito informadas. Con Python, este análisis se puede realizar de manera eficiente y efectiva, y los resultados se pueden visualizar de manera clara y concisa.